12. Veri Okuma#
Veri bilimi ile uğraşıyorsanız zamanınızın büyük çoğunluğunu verileri temin etmek ve bu verileri temizleyip düzenleyerek analize hazır hale getirmek olacaktır. Bu kısım, veri analizinin havalı tarafı olmadığı için genelde çok fazla söz konusu edilmez ama aslında iyi veri bilimcisi olmanın en temel şartı veri okuma ve temizleme yani verileri analize hazır hale getirme işini doğru yapmaktır. Günlük hayatta, gerek profesyonel gerekse akademik çalışmalarda neredeyse hiçbir zaman veriler size analize hazır biçimde gelmez. Çoğu zaman verileri Python dışında bir programdan almanız gerekir. Yeni bir işte ya da projede çalışmaya başladığınızda sizden önceki çalışmalar farklı bir programda yapılmış olabilir. Ya da sıfırdan bir çalışmaya başlasanız bile ihtiyaç duyduğunuz veriler çoğu zaman Python dışında bir formatta gelecektir. Bu nedenle veri biliminin ilk şartı çalışacağınız verileri analize hazır hale getirmeyi bilmektir.
Veri kaynaklarını aşağıdaki şekilde sınıflandırmamız mümkündür:
Düz dosyalar: Bunlar düz metin (txt), ya da tablo formatında (csv, excel vb.) olabilir
Veri tabanı sistemleri: SQL tabanlı sistemlerdir. Bunlar SQL, MySQL, PostgreSQL gibi farklı SQL tipleri olabilir.
HTML: Web kaynaklı dosyalar
İstatistiksel programlar: Genelde ticari amaçlı kullanılan ve ücretli olan SAS, STATA veya SPSS gibi dosyalar.
12.1. Düz Dosyalardan Veri Okuma#
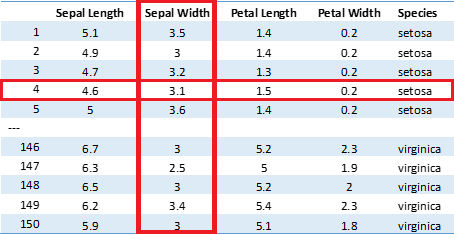
Düz dosyalar genel olarak .txt, .csv gibi tablo formatında veri içeren dosyalardır. Veri analizi açısından bakacak olursak çalışmalarımızda gerçekleştirdiğimiz analizlerin çoğu satır ve sütunlardan oluşan tablolar formatındadır. Bu tablolarda bir satır bir veriyi ya da gözlemi belirtirken sütunlar da bu gözleme ilişkin farklı özellikleri ya da değişkenleri belirtir. Daha önceki bölümlerde gördüğümüz aşağıdaki iris veri setine bakalım. Toplam 150 gözlemden oluşan bu veri setinde her bir satır farklı bir çiçeğe ait ölçümleri göstermektedir. Bu ölçümlerin neler olduğunu da sütunlarda görüyoruz. Veri analizinde metin, csv ya da excel formatındaki dosyalardan okuduğumuz veriler genellikle bu formatta yapılandırılmıştır.
12.1.1. Metin Dosyalarından Veri Okuma#
Metin dosyaları .txt uzantısına sahip düz metin formatında olan dosyalardır. Bir metin dosyasından veri okumak için önce dosyayla bağlantı sağlanmalıdır. Python, open() fonksiyonu bu bağlantıyı sağlar:
baglanti = open('iris.txt', mode = 'r')
Fonksiyondaki ilk argüman dosya ismi, ikinci argüman ise dosyanın hangi modda okunacağıdır. Dosyadan sadece veri okumak için bu argümanı ‘r’ (read) olarak belirtiyoruz. Bağlantıyı okuma modunda kurarak ham veride herhangi bir değişiklik yapmanın önüne geçmiş oluyoruz. Bağlantı sırasında dosyaya veri yazmak için bu argümanı ‘w’ (write) yapmamız gerekir. Bağlantı dosyasının bulunduğu dizin yolunu da açıkça yazmak gerekebilir: “C:/Users/ilker/Desktop/iris.txt” gibi.
Dosyadan veri okumak için sadece bağlantı kurmak yetmez. Şimdi da dosyadan veri okumalıyız. Bunun için de bağlantı üzerinde .read() metodunu kullanıyoruz: veri = baglanti.read().Son olarak kurduğumuz bağlantıyı kapatmamız gerekiyor: baglanti.close()
Şimdi bütün işlemlerin bir arada görelim.
baglanti = open("data/iris.txt", mode="r")
veri = baglanti.read()
baglanti.close()
print(veri[:95])
5.1 3.5 1.4 0.2
4.9 3.0 1.4 0.2
4.7 3.2 1.3 0.2
4.6 3.1 1.5 0.2
5.0 3.6 1.4 0.2
5.4 3.9 1.7 0.4
Aynı işlemi with fonksiyonu ile de yapabiliriz. Bu şekilde .close() metodunu kullanmamıza da gerek kalmaz.
with open("data/iris.txt", mode = 'r') as baglanti:
print(baglanti.read())
5.1 3.5 1.4 0.2
4.9 3.0 1.4 0.2
4.7 3.2 1.3 0.2
4.6 3.1 1.5 0.2
5.0 3.6 1.4 0.2
5.4 3.9 1.7 0.4
4.6 3.4 1.4 0.3
5.0 3.4 1.5 0.2
4.4 2.9 1.4 0.2
4.9 3.1 1.5 0.1
5.4 3.7 1.5 0.2
4.8 3.4 1.6 0.2
4.8 3.0 1.4 0.1
4.3 3.0 1.1 0.1
5.8 4.0 1.2 0.2
5.7 4.4 1.5 0.4
5.4 3.9 1.3 0.4
5.1 3.5 1.4 0.3
5.7 3.8 1.7 0.3
5.1 3.8 1.5 0.3
5.4 3.4 1.7 0.2
5.1 3.7 1.5 0.4
4.6 3.6 1.0 0.2
5.1 3.3 1.7 0.5
4.8 3.4 1.9 0.2
5.0 3.0 1.6 0.2
5.0 3.4 1.6 0.4
5.2 3.5 1.5 0.2
5.2 3.4 1.4 0.2
4.7 3.2 1.6 0.2
4.8 3.1 1.6 0.2
5.4 3.4 1.5 0.4
5.2 4.1 1.5 0.1
5.5 4.2 1.4 0.2
4.9 3.1 1.5 0.2
5.0 3.2 1.2 0.2
5.5 3.5 1.3 0.2
4.9 3.6 1.4 0.1
4.4 3.0 1.3 0.2
5.1 3.4 1.5 0.2
5.0 3.5 1.3 0.3
4.5 2.3 1.3 0.3
4.4 3.2 1.3 0.2
5.0 3.5 1.6 0.6
5.1 3.8 1.9 0.4
4.8 3.0 1.4 0.3
5.1 3.8 1.6 0.2
4.6 3.2 1.4 0.2
5.3 3.7 1.5 0.2
5.0 3.3 1.4 0.2
7.0 3.2 4.7 1.4
6.4 3.2 4.5 1.5
6.9 3.1 4.9 1.5
5.5 2.3 4.0 1.3
6.5 2.8 4.6 1.5
5.7 2.8 4.5 1.3
6.3 3.3 4.7 1.6
4.9 2.4 3.3 1.0
6.6 2.9 4.6 1.3
5.2 2.7 3.9 1.4
5.0 2.0 3.5 1.0
5.9 3.0 4.2 1.5
6.0 2.2 4.0 1.0
6.1 2.9 4.7 1.4
5.6 2.9 3.6 1.3
6.7 3.1 4.4 1.4
5.6 3.0 4.5 1.5
5.8 2.7 4.1 1.0
6.2 2.2 4.5 1.5
5.6 2.5 3.9 1.1
5.9 3.2 4.8 1.8
6.1 2.8 4.0 1.3
6.3 2.5 4.9 1.5
6.1 2.8 4.7 1.2
6.4 2.9 4.3 1.3
6.6 3.0 4.4 1.4
6.8 2.8 4.8 1.4
6.7 3.0 5.0 1.7
6.0 2.9 4.5 1.5
5.7 2.6 3.5 1.0
5.5 2.4 3.8 1.1
5.5 2.4 3.7 1.0
5.8 2.7 3.9 1.2
6.0 2.7 5.1 1.6
5.4 3.0 4.5 1.5
6.0 3.4 4.5 1.6
6.7 3.1 4.7 1.5
6.3 2.3 4.4 1.3
5.6 3.0 4.1 1.3
5.5 2.5 4.0 1.3
5.5 2.6 4.4 1.2
6.1 3.0 4.6 1.4
5.8 2.6 4.0 1.2
5.0 2.3 3.3 1.0
5.6 2.7 4.2 1.3
5.7 3.0 4.2 1.2
5.7 2.9 4.2 1.3
6.2 2.9 4.3 1.3
5.1 2.5 3.0 1.1
5.7 2.8 4.1 1.3
6.3 3.3 6.0 2.5
5.8 2.7 5.1 1.9
7.1 3.0 5.9 2.1
6.3 2.9 5.6 1.8
6.5 3.0 5.8 2.2
7.6 3.0 6.6 2.1
4.9 2.5 4.5 1.7
7.3 2.9 6.3 1.8
6.7 2.5 5.8 1.8
7.2 3.6 6.1 2.5
6.5 3.2 5.1 2.0
6.4 2.7 5.3 1.9
6.8 3.0 5.5 2.1
5.7 2.5 5.0 2.0
5.8 2.8 5.1 2.4
6.4 3.2 5.3 2.3
6.5 3.0 5.5 1.8
7.7 3.8 6.7 2.2
7.7 2.6 6.9 2.3
6.0 2.2 5.0 1.5
6.9 3.2 5.7 2.3
5.6 2.8 4.9 2.0
7.7 2.8 6.7 2.0
6.3 2.7 4.9 1.8
6.7 3.3 5.7 2.1
7.2 3.2 6.0 1.8
6.2 2.8 4.8 1.8
6.1 3.0 4.9 1.8
6.4 2.8 5.6 2.1
7.2 3.0 5.8 1.6
7.4 2.8 6.1 1.9
7.9 3.8 6.4 2.0
6.4 2.8 5.6 2.2
6.3 2.8 5.1 1.5
6.1 2.6 5.6 1.4
7.7 3.0 6.1 2.3
6.3 3.4 5.6 2.4
6.4 3.1 5.5 1.8
6.0 3.0 4.8 1.8
6.9 3.1 5.4 2.1
6.7 3.1 5.6 2.4
6.9 3.1 5.1 2.3
5.8 2.7 5.1 1.9
6.8 3.2 5.9 2.3
6.7 3.3 5.7 2.5
6.7 3.0 5.2 2.3
6.3 2.5 5.0 1.9
6.5 3.0 5.2 2.0
6.2 3.4 5.4 2.3
5.9 3.0 5.1 1.8
Okuyacağınız dosya çok büyükse dosyanın tamamını tek seferde okumak zor olabilir. Bu nedenle bağlantı kurduktan sonra dosya, satır satır okunabilir. Dosyadan verileri satır satır okumak için .readline() metodu kullanılabilir.
with open("data/iris.txt", mode = 'r') as baglanti:
print(baglanti.readline())
print(baglanti.readline())
print(baglanti.readline())
print(baglanti.readline())
5.1 3.5 1.4 0.2
4.9 3.0 1.4 0.2
4.7 3.2 1.3 0.2
4.6 3.1 1.5 0.2
Önceki bölümlerde Python’da veri analizi olan iki paketi, Numpy ve Pandas paketlerini görmüştük. Bu paketlerde de verileri kendi formatlarına uygun olarak okumak için gerekli fonksiyonlar yer almaktadır. Böylece okuyacağınız verileri hangi pakette analiz edeceksek o paketin ilgili fonksiyonlarını kullanarak aktarabiliriz.
12.1.2. Numpy Modülü ile Veri Okuma#
İlgili bölümde de gördüğümüz üzere Numpy modülü özellikle sayısal verileri okumak ve Analiz etmek için çok kullanışlı bir pakettir. Numpy’da düz dosya okumak için kullanılan iki fonksiyon loadtxt() ve genfromtxt() fonksiyonlarıdır.
import numpy as np
dosya = "data/iris.txt"
veri = np.loadtxt(dosya, delimiter="\t")
print(veri[:10, :])
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]]
Loadtxt fonksiyonundaki ikinci argüman olan delimiter, bir satırdaki verilerin birbirlerinden hangi işaretle ayrıldıklarını belirtir. Bizim dosyamızda veriler virgül ile ayrılmış olduğu için argümanda bunu belirtiyoruz. Veriler, örneğin sekme yani tab ile ayrılmışsa virgül yerine \t yazmamız gerekirdi. Çoğu zaman olduğu gibi dosyada ilk satırda sütun başlıkları yer almakta ise bu durumda üçüncü bir argüman olarak skiprows kullanılır. Bu argüman, dosya başından itibaren kaç satırın atlanacağını belirtir.
veri = np.loadtxt(dosya, delimiter="\t", skiprows = 10)
print(veri[:10, :])
[[5.4 3.7 1.5 0.2]
[4.8 3.4 1.6 0.2]
[4.8 3. 1.4 0.1]
[4.3 3. 1.1 0.1]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
[5.4 3.9 1.3 0.4]
[5.1 3.5 1.4 0.3]
[5.7 3.8 1.7 0.3]
[5.1 3.8 1.5 0.3]]
Kullanışlı bir başka argüman da usecols argümanıdır. Bu da orijinal dosyadan hangi sütunların dikkate alınacağını gösterir. Örneğin, sadece 1. ve 3. sütunlardan veri almak istiyorsanız,
veri = np.loadtxt(dosya, delimiter="\t", usecols=[0, 2])
yazmanız gerekir. Python’da sıralamanın sıfırdan başladığını tekrar hatırlayalım. Dosyadan verilerin hangi veri tipinde okunacağını belirtmek için de dtype argümanı kullanılır. Örneğin, okuyacağınız dosyada metin türünde veriler yer alabilir. Verileri metin olarak okumak için loadtxt fonksiyonunda dtype=str yazmanız gerekir.
Çoğu zaman okuyacağımız tabloda farklı türdeki veri sütunları yer alabilir. Bu durumda .loadtxt() metodu işe yaramayacaktır. Bunun yerine .genfromtxt() metodunu kullanabiliriz. Bu metodda, dtype=None olarak belirtirsek program her sütundaki veri tipini otomatik olarak belirlemeye çalışacaktır. Numpy dizileri aynı türde verilerden oluşmak zorundadır. Bu nedenle farklı türdeki verileri okuduğumuz zaman dizilerden oluşan bir dizi elde ederiz. Ana diziyi oluşturan diziler verinin her bir satırını belirtir.
dosya = "data/iris.txt"
veri = np.genfromtxt(dosya, delimiter="\t", dtype=None)
print(veri[:10, :])
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]]
Csv formatındaki dosyaları okumak için kullanılan benzer bir diğer fonksiyon da recfromcsv() metodudur.
dosya = "data/iris.csv"
veri = np.recfromcsv(dosya, delimiter=",", names=True, encoding="utf-8")
print(veri[:10])
[(5.1, 3.5, 1.4, 0.2, 'setosa') (4.9, 3. , 1.4, 0.2, 'setosa')
(4.7, 3.2, 1.3, 0.2, 'setosa') (4.6, 3.1, 1.5, 0.2, 'setosa')
(5. , 3.6, 1.4, 0.2, 'setosa') (5.4, 3.9, 1.7, 0.4, 'setosa')
(4.6, 3.4, 1.4, 0.3, 'setosa') (5. , 3.4, 1.5, 0.2, 'setosa')
(4.4, 2.9, 1.4, 0.2, 'setosa') (4.9, 3.1, 1.5, 0.1, 'setosa')]
12.1.3. Pandas Modülü ile Veri Okuma#
Numpy dizileri çok faydalı ve hızlı olsa da çalışmalarımızın çoğunda ihtiyaç duyduğumuz esnekliği sağlamaz. Gerçekte kullandığımız verilerin çoğu farklı veri tipindeki sütunlardan oluşur (tipik bir excel tablosunu düşünün). Pandas data framelerden ilgili bölümde bahsetmiştik. Şimdi farklı türdeki dosyaları Pandas data frame olarak okumayı görelim. Pandas modülünde csv dosyası okumak için .read_csv() metodu kullanılır.
import pandas as pd
veri = pd.read_csv("data/iris.csv")
print(veri.head())
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
Pandas data frameleri, .values özelliğini kullanarak Numpy dizisine çevirebiliriz.
print(veri.values[:10])
[[5.1 3.5 1.4 0.2 'setosa']
[4.9 3.0 1.4 0.2 'setosa']
[4.7 3.2 1.3 0.2 'setosa']
[4.6 3.1 1.5 0.2 'setosa']
[5.0 3.6 1.4 0.2 'setosa']
[5.4 3.9 1.7 0.4 'setosa']
[4.6 3.4 1.4 0.3 'setosa']
[5.0 3.4 1.5 0.2 'setosa']
[4.4 2.9 1.4 0.2 'setosa']
[4.9 3.1 1.5 0.1 'setosa']]
read_csv() metodu çok sayıda argüman alabilir. Bunlardan birisi dosyadan okunacak satır sayısıdır. Dosyadan, örneğin sadece ilk 3 satırı okumak isityorsak pd.read_csv('dosya_adı', nrows = 3) yazmamız gerekir.
veri = pd.read_csv(dosya, nrows = 3)
print(veri)
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
Benzer şekilde, .read_csv komutu dosyadaki ilk satırın başlık satırı olduğunu varsayar. Dosyada başlık satırı yoksa ve biz herhangi birşey belirtmezse ilk satırdaki veriler sütun başlıkları olarak kabul edilir. Dosyada sütun başlıklarının yer almadığını belirtmek için header=None yazılır. Bu bu durumda, sütunlar 0’dan başlamak üzere sayılarla isimlendirilir.
veri = pd.read_csv("data/iris.csv", header = None)
veri.head()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | sepal_length | sepal_width | petal_length | petal_width | species |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
Dosyada başlık satırı yoksa ve biz başlıkları belirtmek istiyorsak names argümanını kullanarak sütunları isimlendirebiliriz.
dosya = "data/iris.csv"
sutunlar = ['sepal_length','sepal_width','petal_length', 'petal_width','species']
veri = pd.read_csv(dosya, header = None, names = sutunlar, skiprows=1)
veri.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
Varsayalım ki dosyada sütun başlıkları var ama biz bunların yerine başka isimler kullanmak istiyoruz. Bu durumda yine header argümanı ile sütun başlıklarının yer aldığı satırı belirtiyoruz. Sütun başlıkları çoğunlukla ilk satırda yer alır. Python’da numaralandırmanın 0’dan başladığını hatırlayın. O halde ilk satır numarası 0 be kullanacağımız argüman da header = 0 olacaktır. İkinci olarak yine names argümanını kullanarak vereceğimiz yeni isimleri belirtebiliriz.
veri = pd.read_csv(dosya, header = 0, names = sutunlar)
Dosyada NA (Not Available: erişilemez) veya NaN (Not a Number: Bir sayı değil) gibi tanımsız veriler belirli karakterlerle gösteriliyorsa bunları belirtmek için na_values argümanı kullanılır. Örneğin, bir ankete ait sonuçların kaydedildiği dosyada katılımcıların cevap vermediği her soru *** karakterleri ile belirtilmiş olsun. Bu durumda dosyayı doğrudan okumaktansa *** karakteri görülen yerde NA olması gerektiğini belirtmek için na_values = ‘***’ yazılır. Peki tanımsız veriler farklı sütunlarda farklı karakterlerle belirtilmişse ne yaparız? Bu durumda, na_values argümanına verileri sözlük şeklinde tanımlarız. Örneğin, doğum tarihi bilgisi girmeyen katılımcılar için bu alan 0 ile doğum yeri bilgisi girmeyen katılımcılar içinse *** ile belirtiliyor olsun. Bu sütunlarda belirtilen karakterlerin görülmesi durumunda bunların tanımsız olduğunun anlaşılması için na_values = {‘dogum_tarihi’:[‘0’], ‘dogum_yeri’:[‘***’]} yazarız.
Okunacak csv dosyasında sütun ayıracı virgülden farklı ise bu da sep veya delimiter argümanı ile belirtilir. Örneğin, dosyadaki sütunlar genelde olduğu gibi tab / sekme ile ayrılmışsa pd.read_csv() metodunda sep='\t' (veya delimiter=’\t’) yazılır. Csv dosyalarında sütunlar genellikle noktalı virgül veya virgül ile ayrılır. Virgül, varsayılan ayraç olduğundan ayrıca belirtmenize gerek yoktur.
12.2. Excel Dosyalarından Veri Okuma#
Herhalde gerek iş gerekse akademik çalışmalarda en fazla kullanılan dosya türü excel dosyalarıdır. Bu nedenle veri analizinde sık kullanılan programların hemen hepsinde excel dosyalarından veri okumak olanaklıdır. Python’da excel dosyalarından veri okumanın en kolay yolu Pandas modülünü kullanmaktır.
Pandas modülünde excel dosyasından veri okumak için öncelikle dosya ile bağlantı kurmak gerekir. Bunun için de .ExcelFile() metodu kullanılır. Aşağıdaki kodu çalıştırmak için öncesinde openpyxl modülünü kurmanız gerekir.
import pandas as pd
dosya = 'data/iris.xlsx'
veri = pd.ExcelFile(dosya)
Bir defa dosya ile bağlantı kurulduktan sonra, dosyadaki sayfaları .sheet_names() metodu ile görebiliriz. Dosya yolunu tanımlarken dizin de kullanacaksanız dizinler arasında \ yerine / işareti kullanmaya dikkat etmelisiniz. Bildiğiniz gibi Python’da \ işareti, \n, \t gibi kaçış (escape) karakterlerinde kullanıldığı için dosya yolunda bunun yerine / işaretinin kullanılması gerekiyor.
print(veri.sheet_names)
['iris']
İstediğimiz sayfadaki verileri okumak için .parse() metodunu kullanabiliriz. Burada istediğimiz sayfanın ismini metin olarak ya da sayfa numarasını sayı olarak girmemiz mümkün. Bu açıdan, tablo1 = veri.parsel('Sayfa1') veya tablo1 = veri.parsel(0) aynı sonucu verecektir.
Excel dosyalarından veri okurken .parse() argümanına verebileceğimiz farklı argümanlar da bulunmaktadır. Bunlardan ilki skiprow argümanıdır. Bu argümanı kullanarak sayfada okunmadan atlanmasını istediğimiz satır numaralarını liste olarak iletebiliriz. Excel dosyalarında zaman zaman ilk satırlarda tablolar ile ilgili açıklayıcı bilgilere yer verilir. Bunlar bizim çalışmalarımızda işimize yaramayacağından, doğrudan atlanabilir.
tablo1 = veri.parse(0, skiprows=[0,1,2])
Yukarıdaki komut, excel sayfasındaki 1, 2 ve 3. satırları okumadan atlayacaktır. Aynı şekilde dosyadaki sütunların hepsini okumak istemeyebiliriz. Bu durumda parse_cols argümanını kullanarak almak istediğimiz sütun numaralarını iletebiliriz.
tablo1 = veri.parse(0, skiprows=[0], parse_cols=[1,2,3,4])
Bir başka durumda, ilk satırdaki başlıkları okumayıp kendimiz farklı sütun başlıkları vermek isteyebiliriz. Buna neden ihtiyaç duyalım? Aynı formattaki çok sayıda Excel tablosundan veri çekip bunları birleştirecek bir kod yazdığınızı düşünün. Excel tabloları aynı bilgileri içermesine rağmen, sütun başlıkları, dosyayı kaydedene göre değişmiş olabilir. Örneğin, aynı başlık, bir dosyada “Sipariş No”, bir diğerinde “Sip. No.”, bir başkasında “Sipariş Numarası” şeklinde kaydedilmiş olabilir. Bu dosyaları olduğu gibi okumak sonrasında verilerin birleştirilmesinde soruna yol açacaktır. Bu durumda en doğrusu bütün dosyalarda ilk satırı atlayıp sütunlara kendi seçeceğimiz isimleri vermektir.
tablo1 = veri.parse(0, skiprows=[1], parse_cols=[1,2,3,4],
names = ['sepal_boy','sepal_en','petal_boy','petal_en'])
Tüm argümanlara ileteceğimiz değerlerin liste formatında olmasına ve sayısal değerlerin de Python indeks yapısına uygun olarak 0 ile başladığına dikkat edin.
Excel dosyasından veri okumak için kullanılabilecek bir başka Pandas metodu da .read_excel() metodudur. Bu metodun aldığı önemli argümanlar aşağıdaki gibidir.
sheet_name: Verinin okunacağı sayfa adı
header: Sütun başlıklarının yer aldığı satır. Varsayılan olarak sıfırdır.
skiprows: Baştan itibaren atlanacak satır sayısı.
skip_footer: Sondan itibaren atlanacak satır sayısı.
index_col: İndeks olarak kullanılacak sütun.
names: Dosyada başlık satırı yoksa, başlık isimleri liste olarak iletilebilir.
Argümanların tam listesi için pandas.read_excel dokümantasyan linkine bakabilirsiniz.
12.3. Diğer Dosya Türlerinden Veri Okuma#
Sık kullanılan veri analizi programları arasında SAS, STATA, MATLAB ve SPSS gibi programlar da yer alıyor. Bu programlar kullanılarak oluşturulmuş bir dosya ile karşılaşmamız halinde, bunları da Python’a nasıl aktaracağımızı bilmeniz faydalı olacaktır.
12.3.1. SAS Dosyaları#
SAS, özellikle iş uygulamalarında sık kullanılan ticari bir yazılımdır. Statistical Analysis Software kelimelerinin ilk harflerinden oluşmuştur. SAS yazılımında kullanılan dosya uzantısı .sas7bcat veya .sas7bdat’dir.
Python’da SAS dosyalarını okumak için öncelikle Pandas modülünde yer alan .read_sas() metodunu kullanabilirsiniz.
dosya = 'C:/Users/ilker/Desktop/veri_dosyasi.sas7bdat'
veri_tablosu = pd.read_sas(dosya)
Python’da SAS dosyalarını okumanın bir başka yolu da sas7bdat kütüphanesi ve bu kütüphanede yer alan SAS7BDAT modülünü kullanmaktır. Her ne kadar Pandas varken bu modülü önermesem de yine de okuyucuların bilgisi olması amacıyla paylaşıyorum. SAS dosyasını okumak için önce kütüphaneden ilgili modülü aktarmak gerekir.
from sas7bdat import SAS7BDAT
12.3.2. STATA#
STATA, özellikle sosyal bilimler ve ekonomi alanlarında sıkça kullanılan bir istatistiksel analiz programıdır. Statistics and Data sözlerinin bir araya getirilmesinden oluşmuştur. STATA dosyaları .dta uzantısına sahiptir. Artık tahmin edebileceğiniz üzere STATA dosyasını okumak için Pandas modülündeki .read_stata() metodu kullanılabilir.
import pandas as pd
dosya = 'stata_dosyasi.dta'
stata_tablosu = pd.read_stata(dosya)
12.3.3. HDF5 Veri Tipi#
HDF5 ya da Hierarchical Data Format 5, çok büyük ölçekteki ve karmaşık yapıdaki verileri saklamak ve yönetmek üzere geliştirilmiş bir veri modelidir . HDF veri modeli ilk olarak Amerikan, National Center for Supercomputing Applications (NCA) kurumu tarafından geliştirilmiştir. HDF veri yapısı daha sonra kar amacı gütmeyen HDF kurumu tarafından geliştirilmeye devam etmiştir.
Python’un yanı sıra C++, Java, Matlab, Mathematica, R ve Julia gibi çok farklı programlama dilleri için de HDF dosya yapısı ile çalışmaya yönelik kütüphaneler geliştirilmiştir. HDF veri yapısı ile exabyte boyutunda dosyalar ile rahatlıkla çalışılabilir (1 exabyte = 1000 gigabyte).
Python’da HDF5 dosyaları ile çalışabilmek için geliştirilmiş olan modül h5py modülüdür. Bir hdf5 dosyasından veri okumak için bu modüldeki .File() metodu kullanılır.
import h5py
dosya_adi = 'hdf5_dosyasi.hdf5'
veri = h5py.File(dosya_adi, 'r')
Fonksiyondaki ikinci argümanın (‘r’) dosyanın sadece okunması anlamına geldiğini artık biliyoruz. HDF5 dosyasında yer alan verileri görmek için sözlük veri yapısından tanıdığımız .keys() metodunu kullanabiliriz.
for alt_veri in veri.keys():
print(alt_veri)
HDF5 verisinde yer alan alt verilerin kendileri de sözlük yapısında olabilir. Bunların alt verilerini de yine .keys() metodu ile görebilir ya da .value metodu ile verileri inceleyebiliriz.
HDF veri yapısı ve Python’da kullanımı konusunda ayrıntılı bilgi almak isteyen okuyucular Andrew Collette tarafından yazılmış olan Python and HDF5 kitabına başvurabilir.
12.3.4. MATLAB#
Matlab özellikle mühendislik ve temel bilimlerde yoğun olarak kullanılan bir programlama dilidir. Matlab, Matrix Laboratory kelimelerinin birleşmesinden oluşmuştur. Matlab’in ticari bir yazılım olması yaygınlığını sınırlasa da ücretsiz bir yazılım olan Octave Matlab’la neredeyse tamamen aynıdır. Vektör ve matrislerle çalışma prensibine sahip olması nedeniyle Matlab kolay ve hızlı bir programlama dilidir. Özellikle Lineer Cebir uygulamalarında başvurulan bir programdır. Yapay öğrenme, derin öğrenme gibi konularda yakın zamana kadar en fazla kullanılan programlardan birisi Matlab olmakla birlikte son zamanlarda Python daha fazla kullanılmaya başlanmıştır.
Matlab dosyaları .mat uzantısına sahiptir. Matlab dosyalarını okumak için scipy.io modülünde yer alan scipy.io.loadmat(), dosyaları Matlab formatında kaydetmek içinse scipy.io.savemat() fonksiyonlarını kullanabiliriz. Bir .mat dosyası farklı tipte veri nesnelerinden meydana gelmiş olabilir. Python’da .loadmat() metodu ile .mat dosyasını okuduğunuzda veri bir sözlük veri yapısı şeklinde okunur. Sözlükte anahtarlar, .mat dosyasındaki veri nesnelerinin isimleri, değerler ise veri nesnelerini belirtir. Aşağıdaki örnekte, Matlab’da hazır olan örnek dosyalardan gprdata.mat dosyasının Python’dan okunması gösteriliyor. Başında ve sonunda ‘__’ olmayan değişkenler okuduğumuz veri dosyasında yer alan veri nesnelerini ifade ediyor.
import scipy.io
dosya = 'C:/Users/ilker/Desktop/gprdata.mat'
mat_veri = scipy.io.loadmat(dosya)
print(mat_veri.keys())
dict_keys(['__header__', '__version__', '__globals__', 'Xtest', 'Xtrain', 'ytest', 'ytrain'])
print(type(mat_veri['Xtrain']))
<class 'numpy.ndarray'>
import numpy
print(numpy.shape(mat_veri['Xtrain']))
(500, 6)
12.4. İlişkisel Veri Tabanlarından Veri Okuma#
İlişkisel veri tabanlarını basitçe, farklı tablolardan oluşan, her tablodaki kayıtların (satır) belirli bir anahtar değişken (sütun) ile belirlendiği ve tablolar arasındaki ilişkiler için de bu anahtar değişkenlerin kullanıldığı veri tabanlarıdır. İlişkisel veri tabanı ilk olarak 1970 yılında E.F. Codd tarafından önerilmiştir . Bütün ilişkisel veri tabanları veri arama ve düzenleme için SQL (Structured Query Language) dilini kullanır. Kullanılmakta olan birkaç farklı SQL türü vardır: MySQL, PostgreSQL, SQLite vb.
İlişkisel veri tabanının çok sayıda tablodan oluştuğunu söylemiştik. Tabloları Pandas veri çerçevesi gibi düşünebilirsiniz. Bir tablodaki her bir satır bir veri, gözlem veya kaydı temsil eder. Her sütun ise bu tekil gözlemlere ilişkin bir özelliği belirtir.
Örnek olması için bir kütüphanenin veri tabanını oluşturma görevini aldığınızı varsayalım. Hangi verileri saklardınız? Öncelikle kütüphanedeki bütün kitaplar için bir tablo oluşturmak gerekir. Kitap adı, yayınevi, yazarı, kitabın hangi alanla ilgili olduğu vb. bilgileri bu tabloda saklayabilirsiniz. İkinci olarak kütüphane üyelerinin yer aldığı bir tablo oluşturmak gerekecektir. Bu tabloda da üye numarası, adı, soyadı, telefonu, eposta ve adres bilgileri vb. yer alabilir. Üçüncü olarak ödünç verilen kitapları takip edebilmek için bir tablo oluşturmak gerekecektir. Hangi üyenin, hangi kitabı ne zaman aldığı, ne zaman teslim ettiği vb. bilgiler bu tabloda takip edilebilir. Bu tablolar artırılabilir. Örneğin, kitap siparişlerinde kolaylık sağlamak için yayınevlerine ilişkin bilgiler başka bir tabloda yer alabilir. Bütün bu tabloları da anahtar değişkenlerle birbirine bağlamak gerekir. Örneğin, kitap tablosu ile ödünç kitap tablosunu kitap no veya kitap adı gibi bir alanla ilişkilendirmek gerekir ki bir kitap hangi tarihte ödünç verilmiş, o sırada kütüphanede mi ödünç mü verilmiş anlaşılsın. Yine üye tablosu ile ödünç kitap tablosu da üye no gibi bir alanla birleştirilebilir. Böylece hangi üyenin hangi kitapları aldığı, o sırada üzerinde kitap olup olmadığı varsa kaç tane kitap almış olduğu, aldığı kitapları gecikmeli olarak iade edip etmediği takip edilebilsin. Benzer şekilde kitap bilgileri tablosu ile yayınevi tablosu da kitap no gibi bir alanla birleştirilebilir. Bu örnekleri artırmak da mümkündür. Gördüğünüz gibi basit bir kütüphane uygulaması için bile dört tane tablodan oluşan bir ilişkisel veri tabanı kurduk. Çok daha karmaşık verilerin kaydedilip kullanıldığı fabrika, banka, üniversite gibi kuruluşlarda çok daha fazla sayıda tabloya ve değişkene ihtiyaç vardır.
Şimdi tarif ettiğimiz kütüphane veri tabanına ilişkin tabloları görelim. Kitapta gereksiz yer kaplamaması için tablolardaki kayıt sayısını az tuttum.
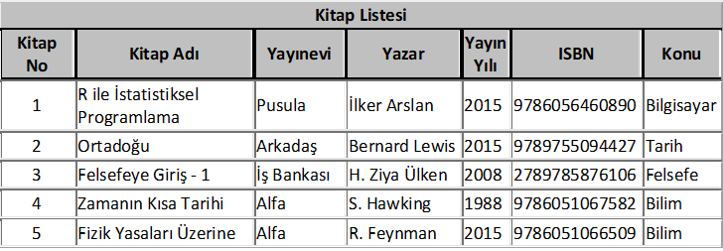
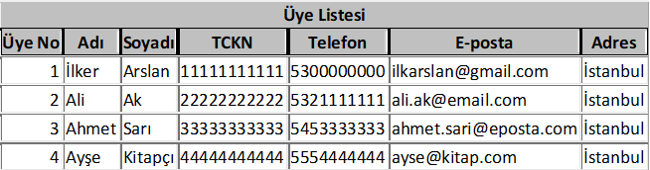
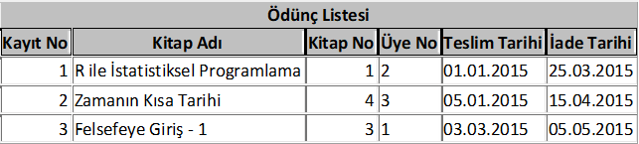
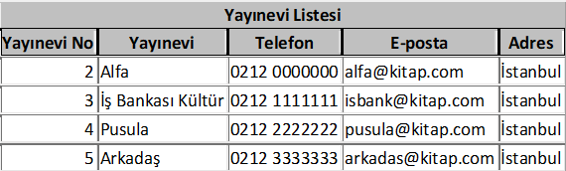
Bu tabloları birbirleriyle ilişkilendirmek için de ilgili alan isimleri kullanılabilir. Yukarıdaki tabloların birbirleriyle ilişkilerini aşağıdaki şekilde daha rahat görebiliriz.
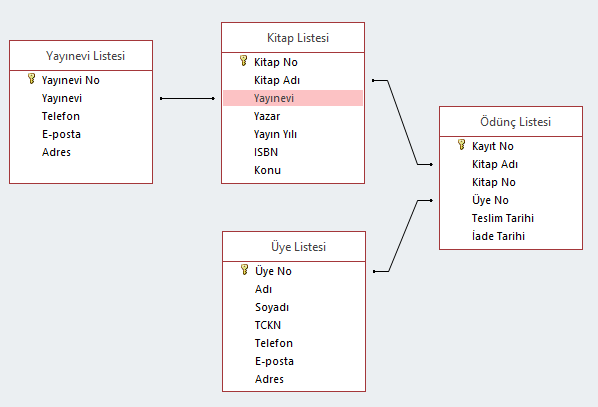
Python kullanarak bir ilişkisel veri tabanına bağlanmak ve bu veri tabanında SQL yardımı ile sorgu yapmak ve veri çekmek mümkündür. Bunun için tabii ki öncelikle veri tabanı ile bağlantı kurmamız gerekir. Bunun için kullanılabilecek çok sayıda modül vardır: sqlalchemy, sqlite3, pypyodbc gibi… Örnek olarak sqlalchemy modülünü inceleyelim. Öncelikle sqlalchemy modülünden create_engine fonksiyonunu aktarıyoruz ve istediğimiz SQL sunucusuna bağlanmak için bu fonksiyonu kullanıyoruz. Çoğunuzun bildiği gibi ilişkisel veri tabanları kurumsal olarak kullanılan veri tabanlarıdır. Bu nedenle, buradaki örnekleri sql sunucusuna erişiminiz olan bir ortamda yani iş yerinizde deneyebilirsiniz. İşinizde ihtiyaç duyduğunuz veriler sql sunucusunda ise ancak siz çalışmalarınızı Python’da yürütmek istiyorsanız burada verilen örnekleri uyarlayarak kullanabilirsiniz. Çoğu zaman SQL sunucusuna bağlantı yetkisi ve kullanmanız gereken sunucu bağlantısı için kurumunuzun bilgi teknolojileri bölümü ile temas kurmanız gerekir.
from sqlalchemy import create_engine
SQL sunucusu ile bağlantı kurmak için kullandığınız create_engine() fonksiyonunda argümanları aşağıdaki format ve sırada kullanmalısınız. Yukarıda da belirttiğim üzere kullanıcı adı, şifre, host, veri tabanı gibi bilgileri (tabii ki erişim yetkiniz varsa) çalıştığınız kurumun bilgi teknolojileri bölümünden almanız gerekiyor.
baglanti = create_engine('sql_türü://kullanıcı:şifre@host:port/veri_tabanı')
SQL türü, sqlite, mysql, postgresql, oracle ya da mssql olabilir. Bağlantı kurulduktan sonra, bağlandığınız veri tabanında hangi tabloların yer aldığını görmek için .table_names() metodunu kullanabilirsiniz.
tablolar = baglanti.table_names()
print(tablolar)
Şimdi oluşturduğumuz bağlantıyı .connect() metodu ile kullanabiliriz.
baglanti = baglan.connect()
Bu bağlantıyı kullanarak SQL sorgusu yapmak için .execute() metodunu kullanmak gerekir.
sorgu1 = baglanti.execute('SELECT * FROM Tablo_1')
Bu kodun çalışması sonucunda oluşturulan sorgu1 bir tablo ya da veri çerçevesi değil bir sqlalchemy modülünde tanımlanmış olan bir sorgu nesnesidir. Şimdi bu sorguyu bir veri çerçevesine çevirmek gerekiyor. Bunun için de Pandas modülünden faydalanacağız. Sorgu nesnesini veri çerçevesine çevirmek için .fetchall() metodu kullanılır.
sonuc_tablo = pd.DataFrame(sorgu1.fetchall())
Bütün sorgu sonucu yerine belirli sayıda satırı çekmek isteyebiliriz. Bunun farklı sebepleri olabilir. Örneğin, sorgu çok büyük olduğu için tamamını aynı anda çekmek mümkün olmayabilir. Bu durumda, .fetchall() yerine .fetchmany() metodunu size argümanı ile birlikte kullanırız. Size argümanı kaç satırı okumak istediğimizi belirtir.
sonuc_tablo = pd.DataFrame(sorgu1.fetchmany(size=100))
Bağlandığınız tablolarda sorgulama yapmak için SQL kodları kullanmanız gerekmektedir. SQL için çok sayıda kaynak ve kitap bulunmaktadır. Başlangıç seviyedeki bilgiler için dileyen okurlar ekler bölümünde yer alan SQL Sorguları bölümüne göz atabilir. Burada giriş seviyesindeki SQL bilgileri verilmiştir.
Tablolarda yaptığımız sorguları veri çerçevesi olarak kaydettikten sonra ilgili bağlantıyı kapatabiliriz. Bağlantıyı kapatmak için .close() metodunu kullanmak gerekir:
sorgu1.close()
Bir defa .create_engine() komutu ile SQL sunucusuna bağlandıktan sonra .connect() metodu ile bağlantıyı canlı hale getirmemiz, .execute() ile SQL sorgusunu gerçekleştirmemiz, .fetchall (veya .fetchmany) komutu ile sorgu nesnesini ver çerçevesine çevirmemiz, veri çerçevesinin sütun isimlerini atamamız ve son olarak bağlantıyı kapatmamız gerekir. Oyda pandas modülünde bunların hepsini tek satırda yapmak mümkündür. Bunun için pandas modülünden .read_sql_query() metodunu kullanmamız gerekiyor.
baglanti = create_engine('sql_türü://kullanıcı_adı:şifre@host:port/veri_tabanı')
sonuc_tablo = pd.read_sql_query('SELECT * FROM Tablo1', baglan)
Görüldüğü gibi bu metod sayesinde sqlalchemy modülünde 3-4 satırda yapılan işi tek satırda yapmak mümkün oluyor. Ancak hala .create_engine() metodu için sqlalchemy modülüne ihtiyaç duyduğumuza dikkat edin.